
Since commercial catastrophe models were introduced in the 1980’s, they have become an integral part of the global (re)insurance industry. Underwriters depend on them to price risk, management uses them to set business strategies, and rating agencies and regulators consider them in their analyses. Yet new scientific discoveries and claims insights regularly reshape our view of risk, and a customized model that is fit-for-purpose one day might quickly become obsolete if it is not updated for changing business practices and advances in our understanding of natural and man-made events in a timely manner.
Despite the sophisticated nature of each new generation of models, new events sometimes expose previously hidden attributes of a particular peril or region. In 2005, Hurricane Katrina caused economic and insured losses in New Orleans far greater than expected because models did not consider the possibility of the city’s levees failing. In 2011, the existence of a previously unknown fault beneath Christchurch and the fact the city sits on an alluvial plain of damp soil created unexpected liquefaction in the New Zealand earthquake. And in 2012, Superstorm Sandy exposed the vulnerability of underground garages and electrical infrastructure in New York City to storm surge, a secondary peril in wind models that did not consider the placement of these risks in pre-Sandy event sets.
Such surprises impact the bottom lines of (re)insurers, who price risk largely based on the losses and volatility suggested by the thousands of simulated events analyzed by a model. However, there is a silver lining for (re)insurers. These events advance modeling capabilities by improving our understanding of the peril’s physics and damage potential. Users can then often incorporate such advances themselves, along with new technologies and best practices for model management, to keep their company’s view of risk current – even if the vendor has not yet released its own updated version – and validate enterprise risk management decisions to important stakeholders.
When creating a resilient internal modeling strategy, (re)insurers must weigh cost, data security, ease of use and dependability. Complementing a core commercial model with in-house data and analytics and standard formulas from regulators, and reconciling any material differences in hazard assumptions or modeled losses, can help companies of all sizes manage resources. Additionally, it protects sensitive information, allows access to the latest technology and support networks and mitigates the impact of a crisis to vital assets – all while developing a unique risk profile.
Figure 1: Building a Resilient Internal Model
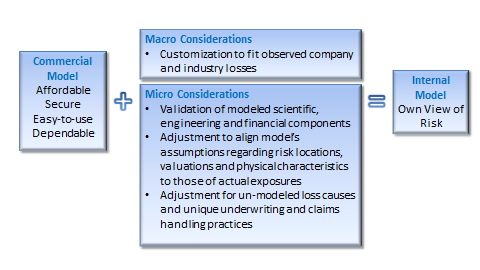
Source: Guy Carpenter
To the extent resources allow, (re)insurers should analyze several macro- and micro-level considerations when evaluating the merits of a given platform. On the macro level, unless a company’s underwriting and claims data dominated the vendor’s development methodology, customization is almost always desirable, especially at the bottom of the loss curve where there is more claim data; if a large insurer with robust exposure and claims data is heavily involved in the vendor’s product development, the model’s vulnerability assumptions and loss payout and developments patterns will likely mirror that of the company itself, so less customization is necessary. Either way, users should validate modeled losses against historical claims from both their own company and industry perspectives, taking care to adjust for inflation, exposure changes or non-modeled perils, to confirm the reasonability of return periods in portfolio and industry occurrence and aggregate exceedance-probability curves. Without this important step, insurers may find their modeled loss curves differ materially from observed historical results, as illustrated below.
Figure 2: Loss Analysis By Return Period
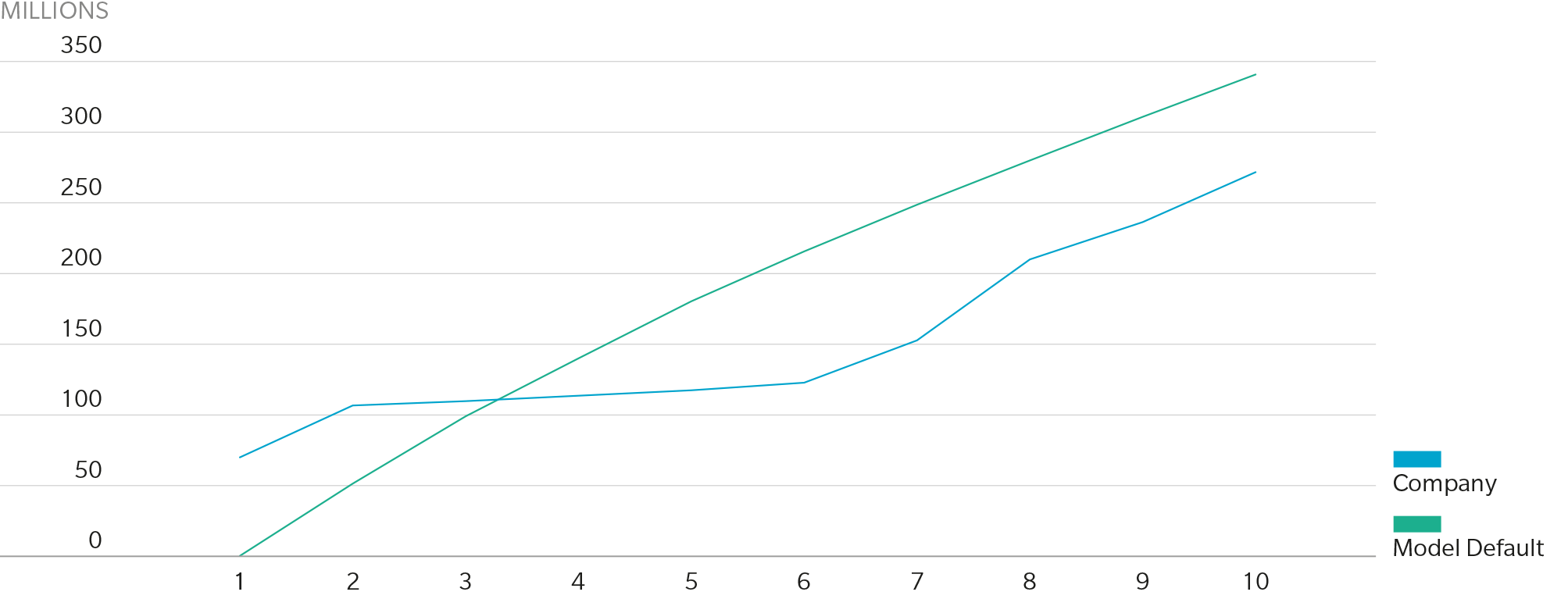
Source: Guy Carpenter Analysis
A micro-level review of model assumptions and shortcomings can further narrow the odds of a “shock” loss. As such, it is critical to precisely identify risks’ physical locations and characteristics as loss estimates may vary widely within a short distance - especially for flood, where elevation is an important factor. When a model’s geocoding engine or a national address database cannot assign location, there are several disaggregation methodologies available, but each produces different loss estimates. European companies will need to be particularly careful regarding data quality and integrity as the new General Data Protection Regulation, which may mean less specific location data is collected, takes effect.
Equally as important as location is a risk’s physical characteristics, as a model will estimate a range of possibilities without this information. If the assumption regarding year of construction, for example, differs materially from the insurer’s actual distribution, modeled losses for risks with unknown construction years may be under or overestimated. The exhibit below illustrates the difference between an insurer’s actual data and a model’s assumed year of construction distribution based on regional census data in Portugal. In this case, the model assumes an older distribution than the actual data shows, so losses on risks with unknown construction years may be overstated.
Figure 3: Year Built: Census 2011 vs. Company Homeowners Portfolio
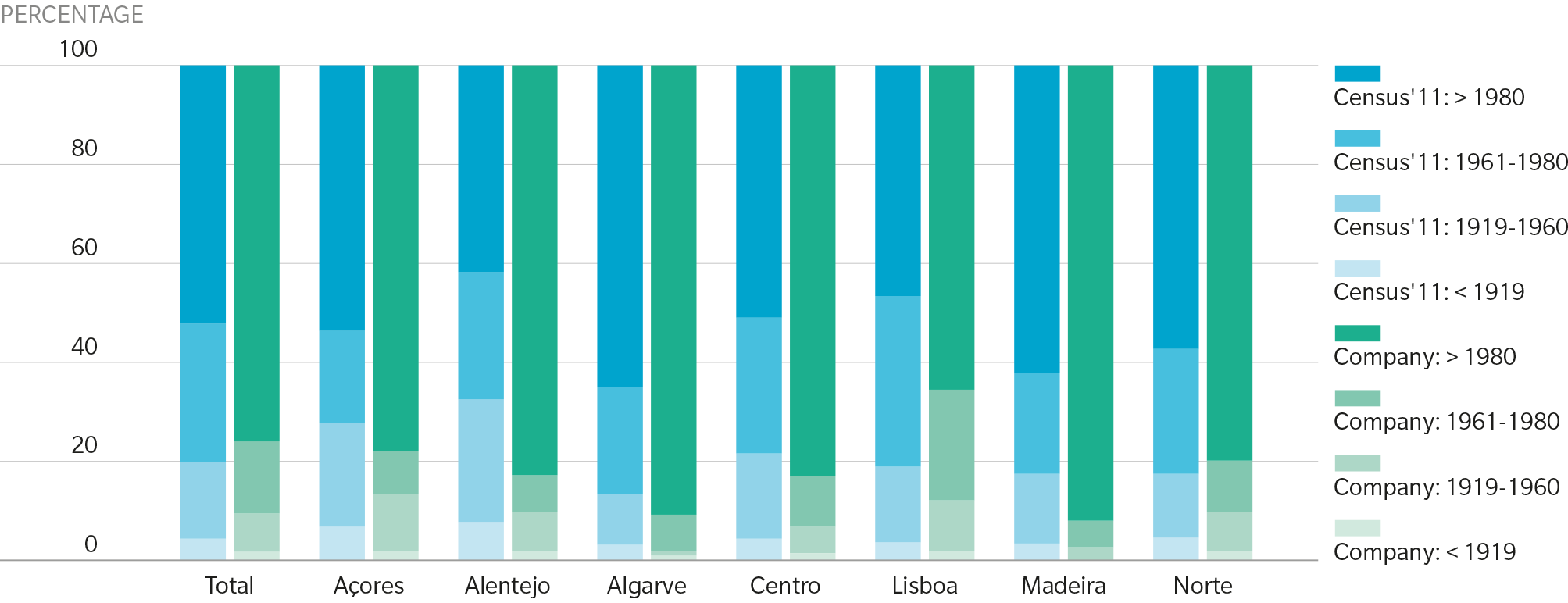
Source: Guy Carpenter Analysis
There is also no database of agreed property, contents or business interruption valuations, so if a model’s assumed valuations are under or overstated, the damage function may be inflated or diminished to balance to historical industry losses.
Finally, companies must also adjust “off-the-shelf” models for missing components. Examples include overlooked exposures like a detached garage; new underwriting guidelines, policy wordings or regulations; or the treatment of sub-perils, such as a tsunami resulting from an earthquake. Loss adjustment difficulties are also not always adequately addressed in models. Loss leakage – such as when adjusters cannot separate covered wind loss from excluded storm surge loss – can inflate results, and complex events can drive higher labor and material costs or unusual delays. Users must also consider the cascading impact of failed risk mitigation measures, such as the malfunction of cooling generators in the Fukushima Nuclear Power Plant after the Tohoku Earthquake.
If an insurer performs regular, macro-level analyses of its model, validating estimated losses against historical experience and new views of risk, while also supplementing missing or inadequate micro-level components appropriately, it can construct a more resilient modeling strategy that minimizes the possibility of model failure and maximizes opportunities for profitable growth.
